
Introduction
Modern enterprises increasingly depend on scalable, automated infrastructure to sustain data velocity and competitive positioning. AWS & GCP Web Scraping for Real-Time Cloud-Based Pipelines has emerged as a foundational capability for organizations that require high-frequency data acquisition across distributed digital environments. From tracking market movements to monitoring product ecosystems, cloud-integrated scraping architectures deliver the precision and throughput that legacy systems simply cannot match.
The growing complexity of digital data sources demands intelligent collection strategies built on resilient infrastructure. Enterprise App Crawling plays a significant role in helping businesses tap into structured and unstructured data at scale, bridging the gap between raw digital information and actionable business intelligence. As the volume of enterprise data expands across platforms, the need for cloud-native scraping pipelines grows accordingly.
This case study documents how we designed and deployed a purpose-built cloud scraping solution for a technology-driven enterprise client. By integrating AWS Data Scraping for IT Insights with advanced pipeline orchestration, the engagement resulted in dramatically faster data operations, reduced infrastructure overhead, and improved decision-making timelines across the client's core business functions.
The Client
A prominent technology services firm operating across multiple verticals approached us seeking to modernize its data acquisition infrastructure. The company managed a wide portfolio of digital intelligence operations but was constrained by outdated collection methods that slowed processing speed and increased operational costs. Their internal teams were spending considerable time managing manual workflows rather than focusing on analysis and strategy.
To address these constraints, the client sought to implement AWS & GCP Web Scraping for Real-Time Cloud-Based Pipelines across their core data functions. Their immediate priority was building a system capable of pulling large volumes of structured enterprise data continuously without performance degradation or latency spikes. Web Scraping Google Cloud for Competitive Intelligence was identified early as a strategic component, particularly for monitoring competitor activity and tracking sector-wide shifts in technology pricing and product availability.
The client also required a solution built for long-term scalability. With expansion plans covering new geographic markets and additional data verticals, their infrastructure needed to accommodate increased workload without architectural rebuilds. They needed a partner capable of designing a cloud-native pipeline that would grow with their business while maintaining the highest standards of data accuracy and operational reliability.
The Challenge
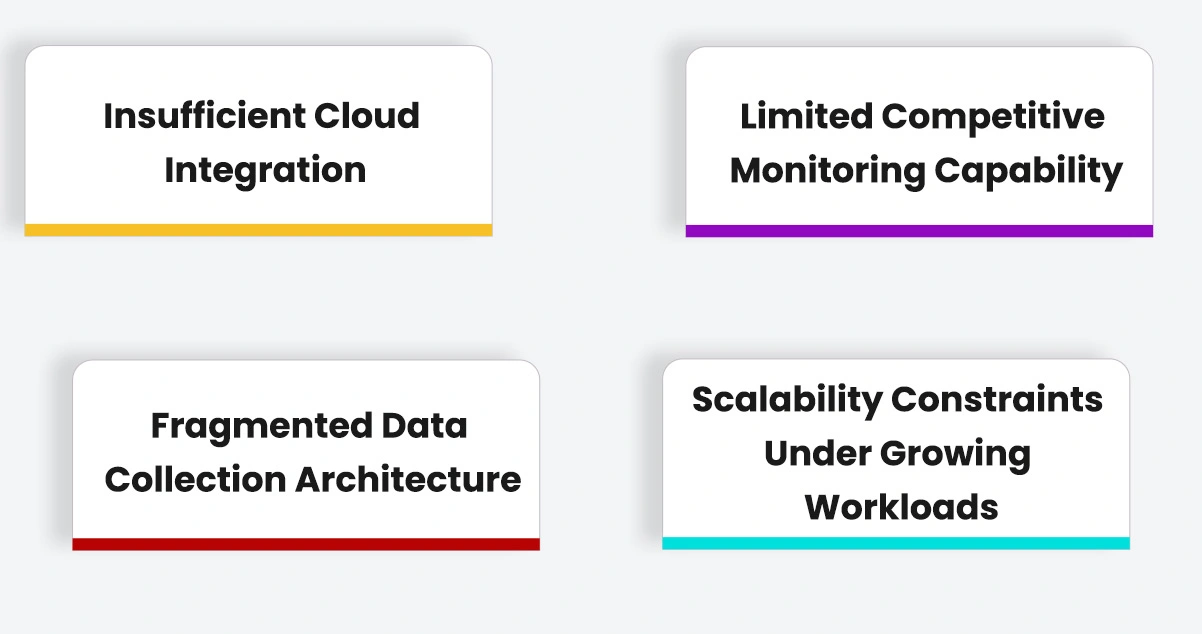
The client encountered several deep-rooted obstacles that were directly impeding their data operations efficiency and limiting their capacity to act on time-sensitive intelligence.
- Fragmented Data Collection Architecture
Teams lacked a centralized system capable of delivering Scrape Enterprise Level Data in Real Time, leading to delayed reporting cycles and misaligned business strategies. - Insufficient Cloud Integration
Without proper Web Scraping Services embedded within cloud infrastructure, the client's pipelines regularly experienced downtime and throughput limitations that impacted downstream analytics. - Limited Competitive Monitoring Capability
The absence of automated, continuous monitoring mechanisms left the client reacting to market shifts rather than anticipating them. Real-time visibility into competitor pricing, product changes, and market positioning was largely unavailable. - Scalability Constraints Under Growing Workloads
As data requirements expanded across new product categories and regional markets, the existing system struggled to scale without manual intervention. Infrastructure rigidity prevented the client from responding to sudden spikes in data demand, reducing operational agility considerably.
The Solution
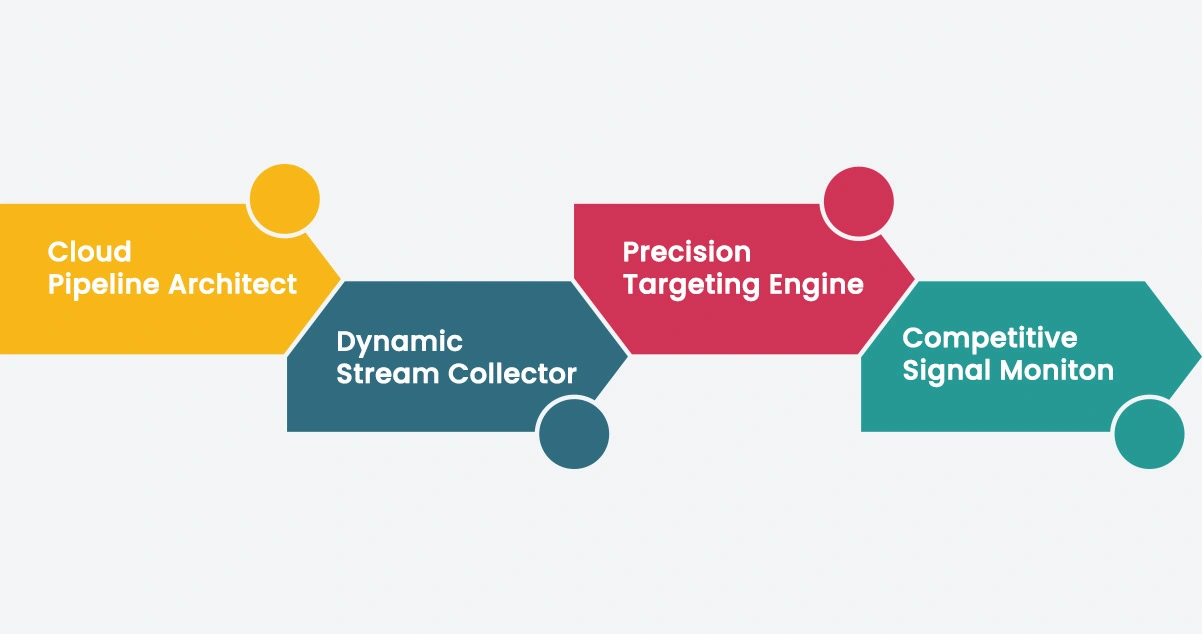
We engineered a modular, cloud-native scraping ecosystem designed to address each challenge with precision and built-in scalability.
- Cloud Pipeline Architect
A unified pipeline framework built across AWS and GCP environments to execute AWS & GCP Web Scraping for Real-Time Cloud-Based Pipelines with consistent throughput, intelligent load balancing, and automated failover mechanisms for uninterrupted data delivery. - Dynamic Stream Collector
A high-frequency collection layer powered by Live Crawler Data Scraping that enables continuous ingestion from multiple target sources simultaneously. This component ensures real-time data availability across all connected pipeline nodes without manual triggering or batch delays. - Precision Targeting Engine
Deploys AWS & GCP Scraper API protocols to identify, isolate, and extract structured enterprise data from complex digital environments. This engine adapts dynamically to structural changes in target sources, maintaining extraction accuracy across volatile web environments. - Competitive Signal Monitor
Applies Web Scraping Google Cloud for Competitive Intelligence to track competitor product catalogs, pricing behaviors, and content updates on a continuous basis. Outputs are structured into actionable datasets and delivered to analytics dashboards in near real time.
Implementation Process
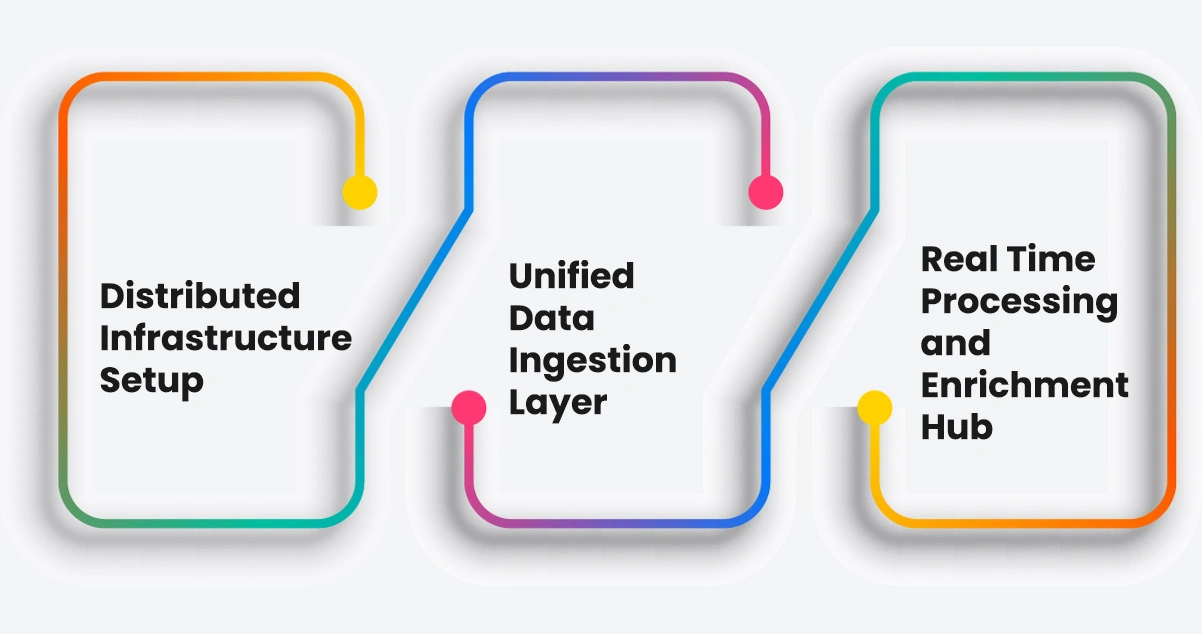
The deployment followed a disciplined, phase-based approach ensuring stability, accuracy, and performance at every stage of integration.
- Distributed Infrastructure Setup
Cloud environments on both AWS and GCP were configured with dedicated scraping nodes, auto-scaling policies, and data routing logic. AWS Data Scraping for IT Insights was embedded at the infrastructure layer to support continuous monitoring of technology-sector data sources across all active pipelines. - Unified Data Ingestion Layer
A centralized ingestion framework was built to consolidate incoming data streams into a single normalized format. This layer applied validation protocols and deduplication logic to ensure that all data entering the pipeline met strict quality thresholds before forwarding to processing stages. - Real-Time Processing and Enrichment Hub
Raw data was passed through enrichment modules that applied classification, tagging, and contextual formatting. Scrape Enterprise Level Data in Real Time capabilities were activated at this stage, allowing the client to access processed intelligence within seconds of original data capture rather than waiting for scheduled batch cycles.
Results & Impact
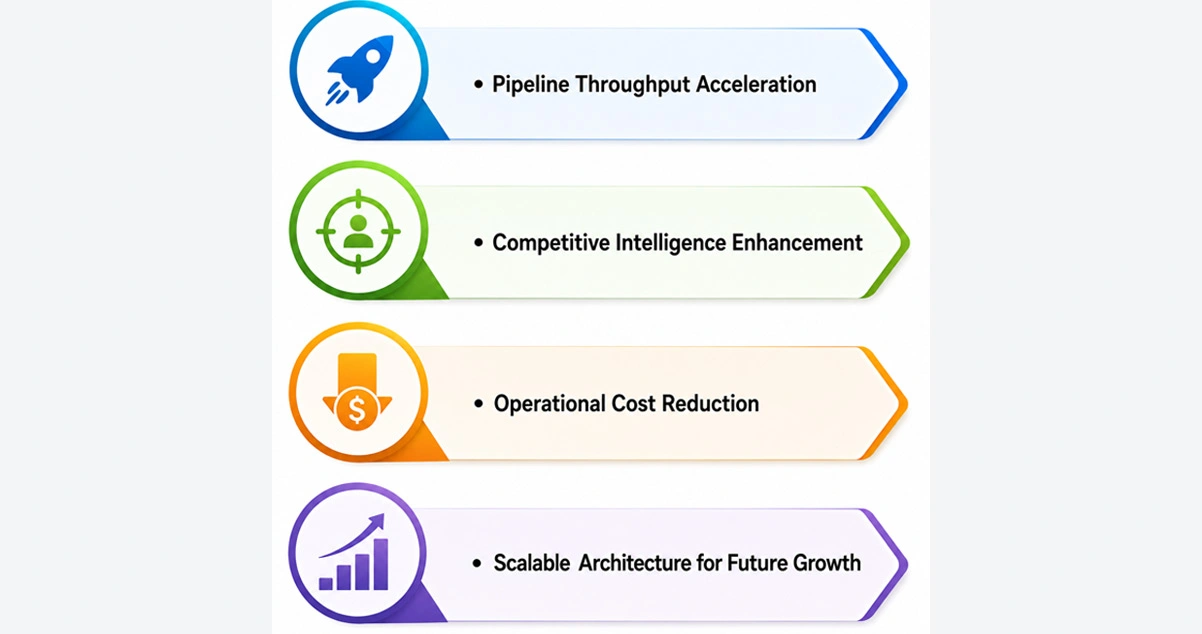
The deployment generated measurable improvements across data performance, operational efficiency, and strategic responsiveness.
- Pipeline Throughput Acceleration
The client achieved consistent real-time data availability across all active monitoring functions, with AWS & GCP Scraper API integration reducing average data delivery latency significantly. - Competitive Intelligence Enhancement
Automated monitoring through Web Scraping Google Cloud for Competitive Intelligence gave the client continuous visibility into competitor activity, enabling faster responses to pricing shifts and product launches across their target market segments. - Operational Cost Reduction
Eliminating manual collection workflows and consolidating infrastructure onto cloud-native platforms reduced overhead costs considerably. Teams previously allocated to data management were redeployed toward higher-value analytical functions, improving overall productivity. - Scalable Architecture for Future Growth
The modular pipeline design allowed the client to onboard new data verticals without architectural redesign. Scrape Enterprise Level Data in Real Time capabilities scaled seamlessly alongside business expansion, accommodating increased workload without performance compromise.
Key Highlights
-
Cloud-Native Pipeline Performance
Delivers continuous, high-velocity data operations through AWS & GCP Web Scraping for Real-Time Cloud-Based Pipelines, combining multi-cloud redundancy with intelligent load distribution for consistent, enterprise-grade throughput. -
IT Intelligence Infrastructure
Strengthens organizational decision-making by embedding AWS Data Scraping for IT Insights across technology monitoring workflows, providing accurate, structured intelligence from complex digital ecosystems at scale. -
Competitive Market Visibility
Enables real-time tracking of competitor behavior and pricing dynamics through AWS & GCP Scraper API configurations, delivering structured outputs that support agile market positioning and faster strategic responses.
Use Cases
- Technology Sector Monitoring
IT Data Intelligence empowers technology teams to continuously track software pricing, product releases, and vendor activity using AWS Data Scraping for IT Insights, enabling proactive strategy adjustments based on accurate, current market data. - Sensitive and Complex Source Extraction
Advanced Data Acquisition applies Deep and Dark Web Scraping methodologies to extract structured intelligence from hard-to-reach digital environments, supporting compliance teams, cybersecurity analysts, and enterprise risk functions with reliable, high-depth data sourcing. - Competitive Benchmarking Operations
Market Position Tracking enables strategy teams to monitor competitor catalog changes, pricing updates, and product availability using Web Scraping Google Cloud for Competitive Intelligence for sustained market advantage. - Enterprise Data Pipeline Scaling
Infrastructure Expansion Planning allows operations teams to design and deploy scalable scraping pipelines that grow alongside business demands, supporting seamless data continuity across expanding geographic and vertical markets.
Client’s Testimonial

Partnering with Mobile App Scraping transformed how our organization handles data acquisition and pipeline management. The implementation of AWS & GCP Web Scraping for Real-Time Cloud-Based Pipelines gave us the real-time visibility we had been missing for years. The speed, accuracy, and reliability of the solution exceeded our expectations, and the AWS & GCP Scraper API integration made scaling across our data functions remarkably straightforward.
– Emeway Ellwood, Head of Data Infrastructure & Cloud Operations
Conclusion
Sustained competitiveness in today's data-intensive environment requires infrastructure that can collect, process, and deliver intelligence at the pace of the market. AWS & GCP Web Scraping for Real-Time Cloud-Based Pipelines provides exactly that; a robust, cloud-native foundation for enterprise data operations that scales with demand and eliminates the bottlenecks that slow critical decisions.
Scrape Enterprise Level Data in Real Time capabilities ensure that every insight reaching your decision-makers is current, accurate, and structured for immediate action, giving your business the operational edge it needs to stay relevant in fast-moving markets. Contact Mobile App Scraping today to learn how our cloud-native scraping solutions can accelerate your data operations and power your enterprise pipelines.