
What is the Best Approach to Handling JavaScript-Heavy Websites in Web Scraping Scalable Pipelines?
Introduction
Modern data ecosystems rely heavily on real-time and interactive web applications, which makes extraction increasingly complex. Traditional scraping methods often fail when pages depend on client-side rendering, delayed API calls, or asynchronous content loading. Businesses adopting Web Scraping Services must therefore rethink their infrastructure to handle such dynamic environments efficiently.
One of the core challenges in this space is Handling JavaScript-Heavy Websites in Web Scraping, where content is not immediately available in static HTML. Instead, it is generated dynamically after scripts execute in the browser. Scalable pipelines must incorporate rendering engines, queue-based task management, and retry mechanisms to handle failures caused by script-heavy pages.
Additionally, performance optimization becomes critical when dealing with thousands of concurrent URLs. Without proper architecture, scraping systems may become slow, unstable, or resource-intensive. As digital platforms continue to evolve, mastering dynamic rendering is essential for any enterprise aiming to build robust and future-ready data extraction systems.
Optimizing Script Driven Data Extraction Workflows
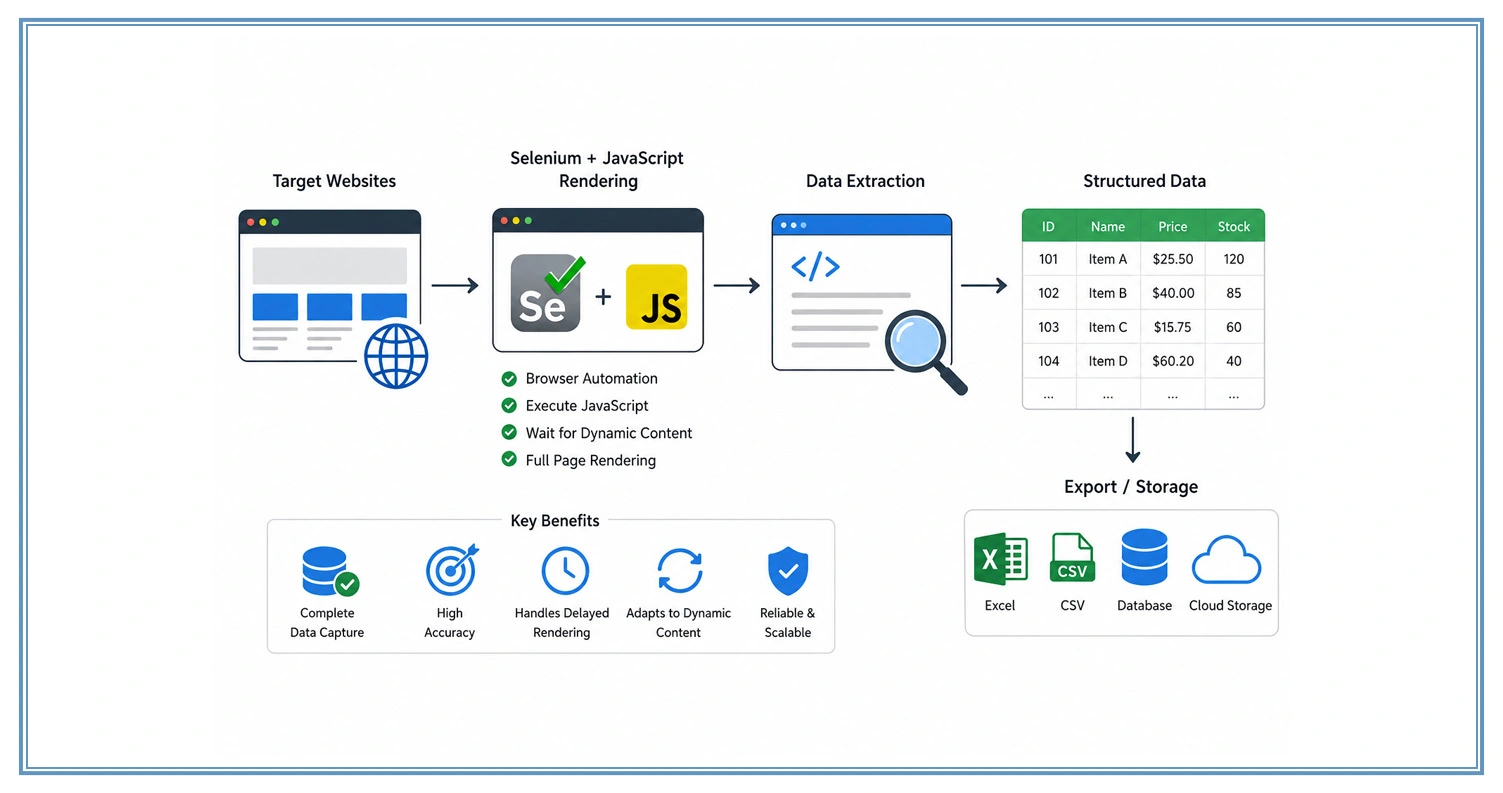
Modern data ecosystems require structured systems capable of processing highly interactive web environments where content is generated dynamically. Many enterprises depend on App Data Scraping Services to organize large-scale extraction pipelines that handle unpredictable page behaviors and delayed rendering events. A commonly adopted technique, Web Scraping Using Selenium & JS, allows controlled browser automation, ensuring that all script-generated elements are fully loaded before extraction begins.
This reduces incomplete datasets and improves overall reliability across complex digital platforms. Additionally, applying How to Scrape JavaScript-Heavy Websites Effectively helps developers design optimized workflows that balance rendering speed with data accuracy, especially when dealing with frequently changing interfaces and asynchronous content delivery mechanisms.
| Challenge Area | Operational Impact | Optimization Method |
|---|---|---|
| Delayed Rendering | Missing structured fields | Controlled browser waits |
| Script Execution Lag | Inconsistent outputs | Automated DOM validation |
| UI Element Shift | Broken selectors | Adaptive parsing logic |
Efficient pipeline design also requires queue management, retry logic, and selective rendering to avoid unnecessary browser overhead. Engineers implement caching layers and incremental updates to reduce redundant requests while maintaining data freshness.
By isolating execution contexts and monitoring response timing, systems achieve higher throughput and stability. Such optimizations also support long-term scalability across multi-region scraping infrastructures handling diverse data sources.
Enhancing Scalability in Data Processing Systems
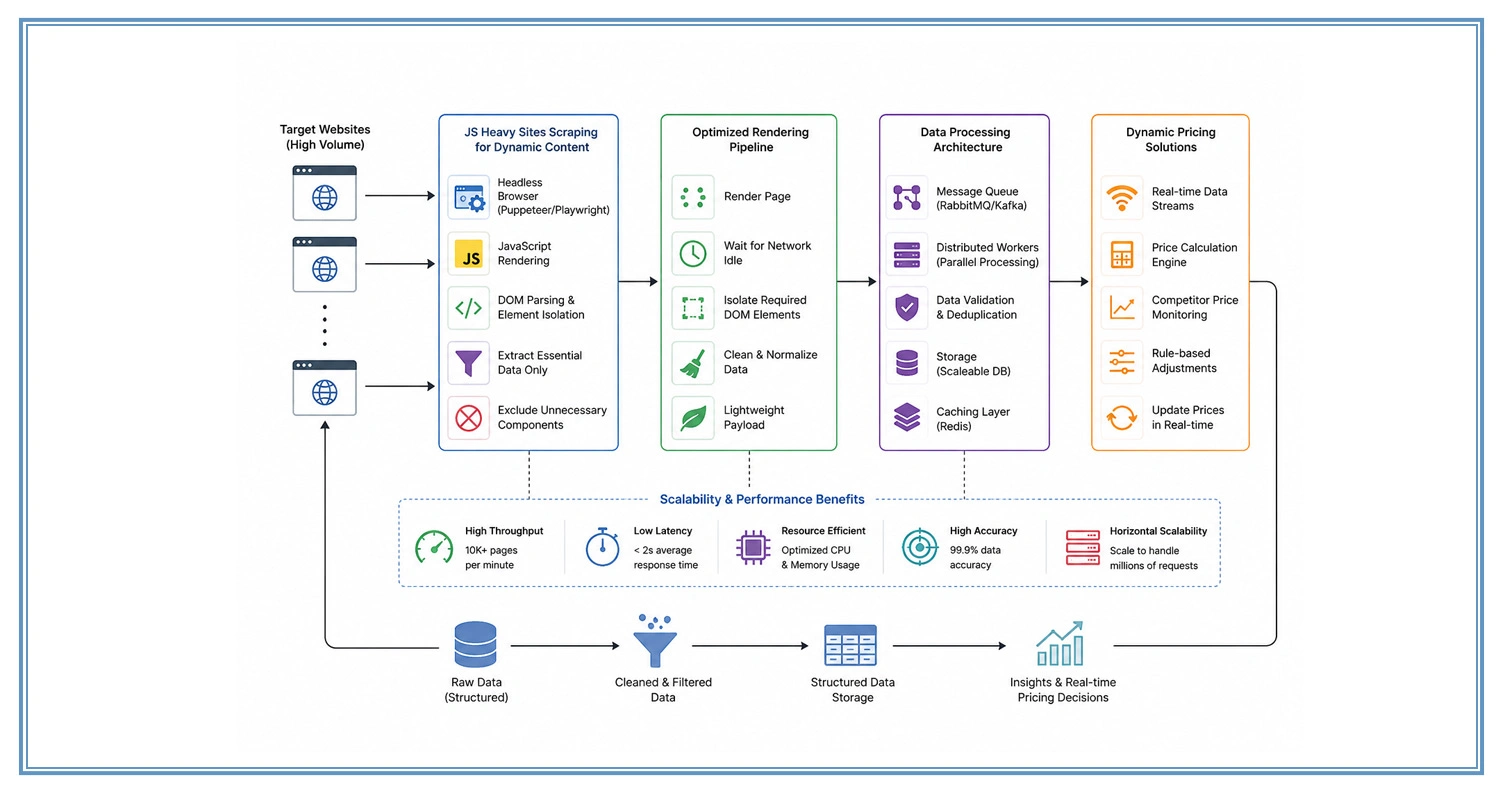
High-volume extraction environments demand architectures capable of handling intensive rendering workloads without degrading performance. Many modern Dynamic Pricing Solutions depend on real-time and accurate data streams to adjust pricing models dynamically across competitive markets.
To support these systems, engineers optimize rendering pipelines that minimize latency and resource consumption. JS Heavy Sites Scraping for Dynamic Content plays a crucial role in isolating only essential DOM elements, ensuring that unnecessary page components are excluded from processing to improve efficiency and speed.
| Performance Issue | Root Cause | Optimization Strategy |
|---|---|---|
| High Latency | Full-page rendering | Targeted element extraction |
| Resource Bottleneck | Heavy script execution | Parallel task execution |
| Slow Response Cycles | Blocking requests | Asynchronous processing |
Further optimization strategies include parallel processing, distributed task queues, and adaptive throttling mechanisms that adjust based on server response patterns. Engineers often implement lightweight session handling to reduce memory usage while maintaining persistence across requests.
Logging and monitoring systems help identify slow endpoints and optimize execution paths. Additionally, data normalization layers ensure consistency before storage, enabling smoother downstream analytics. This structure supports predictable scaling across rapidly changing digital environments.
Improving Reliability in Distributed Data Systems
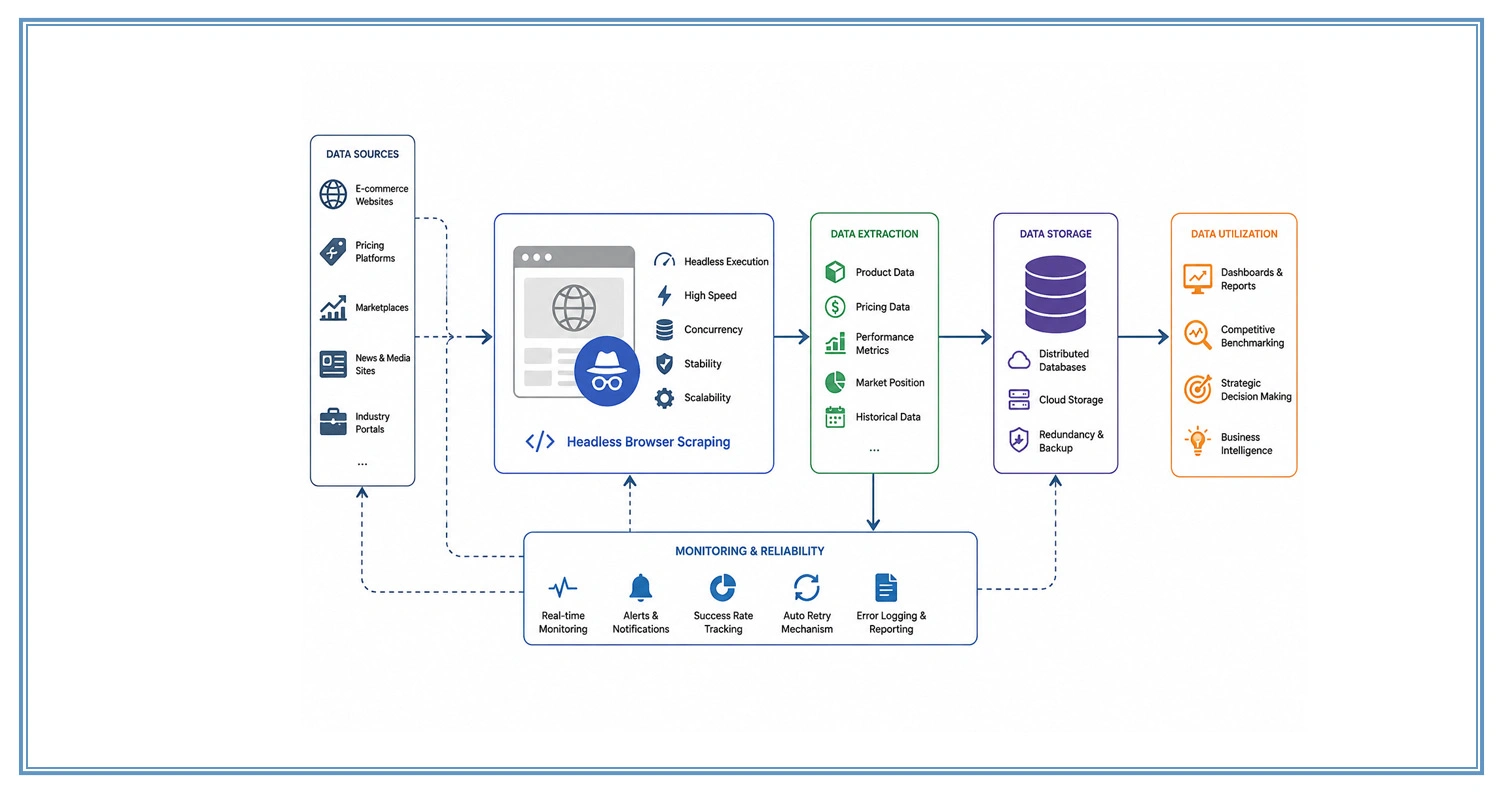
In large-scale data ecosystems, maintaining consistent extraction performance is essential for accurate analysis and strategic decision-making. Competitive Benchmarking Services rely on continuous data collection across multiple sources to evaluate performance metrics, pricing behavior, and market positioning.
However, instability in script-driven environments can lead to incomplete or inconsistent datasets. Headless Browser Scraping in Heavy Dynamic Sites addresses this challenge by enabling background execution without graphical interface overhead, improving speed, concurrency, and overall system stability in distributed architectures.
| Reliability Challenge | Underlying Cause | System Enhancement |
|---|---|---|
| Data Loss Events | Network interruptions | Automated retry mechanisms |
| Session Failures | Timeout limitations | Session recovery logic |
| Incomplete Outputs | Script interruptions | Smart execution checkpoints |
To further strengthen reliability, systems incorporate automated retry workflows, intelligent load balancing, and self-healing execution pipelines. Monitoring dashboards track extraction success rates and highlight anomalies in real time. Data validation layers ensure consistency before storage, reducing the risk of corrupted outputs.
Containerized deployments improve scalability across multiple nodes, enhancing fault tolerance and operational efficiency. Together, these improvements create a resilient infrastructure capable of sustaining high-demand data operations. This ensures continuous performance across complex, high-demand data ecosystems.
How Mobile App Scraping Can Help You?
Many modern platforms replicate web behavior inside mobile ecosystems, making extraction even more complex. Efficient systems dealing with Handling JavaScript-Heavy Websites in Web Scraping often extend their architecture to mobile environments for complete data visibility.
Key advantages include:
- Capturing real-time application behavior patterns
- Extracting structured and unstructured datasets simultaneously
- Identifying user interaction flows across app screens
- Improving dataset freshness for analytical models
- Supporting multi-platform data consolidation
- Enhancing accuracy in market trend evaluation
These capabilities make mobile extraction a powerful extension of traditional scraping systems. Businesses often combine it with How to Scrape JavaScript-Heavy Websites Effectively to ensure unified data pipelines across web and mobile ecosystems, improving overall coverage and analytical precision.
Conclusion
Efficient data extraction in modern ecosystems depends heavily on adaptability and scalable design. In environments shaped by Handling JavaScript-Heavy Websites in Web Scraping, traditional methods fall short without rendering intelligence and asynchronous handling mechanisms. Businesses must therefore evolve toward more resilient architectures that support dynamic execution flows.
One of the most practical advancements comes from integrating Web Scraping Using Selenium & JS, which enables controlled browser automation and reliable data capture even from highly interactive web applications. Start building resilient scraping pipelines today with Mobile App Scraping to transform raw web complexity into structured business intelligence.